Table of contents
-
Creating the model structure: >
- A structure for polynomial trend models
- A structure for dynamic regression models
- A structure for harmonic trend models
- A structure for autoregresive models
- A structure for overdispersed models
- Handling multiple structural blocks
- Handling multiple linear predictors
- Handling unknown components in the planning matrix
- Special priors
-
Advanced examples:>
Introduction
This vignette is intended as an introduction to the usage of the kDGLM package, which offers routines for Bayesian analysis of Dynamic Generalized Linear Models, including fitting (filtering and smoothing), forecasting, sampling, intervention and automated monitoring, following the theory developed and/or explored in Kalman (1960), West and Harrison (1997) and Alves et al. (2024).
In this document we will focus exclusively in the usage of the package and will only briefly mention the theory behind these models and only with the intention of highlighting the notation. We highly recommend all users to read the theoretical work (dos Santos et al., 2024) in which we based this package.
This document is organized in the following order:
- First we introduce the notations and the class of models we will be dealing with;
- Next we present the details about the specification of the model structure, offering tools that allow for an easy, fast and (hopefully) intuitive way of defining models;
- In the following section we discuss details about how the user can specify the observational model;
- Then we present some basic examples of model fitting, also showing the auxiliary functions that help the user to analyse the fitted model. We also show tools for easy model selection;
- Lastly, we present a variety of advanced examples, combining the basic features shown in previous sections to create more complex models;
Notation
In this section, we assume the user’s interest lies in analyzing a Time Series , which adheres to the model described by :
The model comprises:
- , the outcome, is an -dimensional vector of observed variable.
- , representing the unknown parameters (latent states), is an -dimensional vector, consistently dimensioned across observations.
- , the linear predictors, is a -dimensional vector indicating the linear transformation of the latent states. As per , is assumed to be (approximately) Normally distributed at all times and directly corresponds to the observational parameters , through a one-to-one correspondence .
- , the observational parameters, is an -dimensional vector defining the model’s observational aspects. Typically, , but this may not hold in some special cases, such as in the Multinomial model, where .
- , a distribution from the Exponential Family indexed by . Pre-determines the values and , along with the link function .
- , the link function, establishes a one-to-one correspondence between and .
- , the design matrix, is a user-defined, mostly known, matrix of size .
- , the evolution matrix, is a user-defined, mostly known, matrix of size .
- , the drift, is a known -dimensional vector, typically set to except for model interventions (refer to subsection ).
- , a known covariance matrix of size , is specified by the user.
Per , we define as the cumulative information after observing the first data points, with denoting pre-observation knowledge of the process .
The specification of follows , section 6.3, where . Here, (the discount matrix) is an matrix with values between and , represents the Hadamard product, and signifies Hadamard division. is another known matrix specified by the user. This formulation implies that if entries are all , and entries are all , the model equates to a Generalized Linear Model.
A prototypical example within the general model framework is the Poisson model augmented with a dynamic level featuring linear growth and a single covariate :
In this model, denotes the Poisson distribution; the model dimensions are ; the state vector is with dimension ; the link function is the natural logarithm; and the matrices and are defined as:
Consider now a Normal model with unknown mean and unknown precision :
For this case, represents the Normal distribution; the model dimensions are and ; the state vector is with dimension ; the link function and matrices , are:
This configuration introduces observational parameters, necessitating linear predictors. The first linear predictor pertains to the location parameter of the Normal distribution and includes a linear growth model and the covariate . The second linear predictor, associated with the precision parameter, models log precision as an autoregressive (AR) process. We express this model in terms of an Extended Kalman Filter (Kalman, 1960; West and Harrison, 1997). This formulation aligns with the concept of a traditional Stochastic Volatility model, as highlighted by Alves et al. (2024).
Both the Normal and Poisson models illustrate univariate cases. However, the general model also accommodates multivariate outcomes, such as in the multinomial case. Consider a vector of counts , with and . The model is:
In this multinomial model, is the Multinomial distribution; the model dimensions are , and ; the state vector is ; and are identity matrices of size ; and the link function maps in as:
Note that in the Multinomial distribuition, and . Thus, only linear predictors are necessary to describe this model.
It’s important to emphasize that while we have chosen to illustrate simple model structures, such as a random walk in the log odds for each outcome, neither the general model framework nor the kDGLM package restricts to these configurations. Analysts have the flexibility to tailor models to their specific contexts, including the incorporation of additional latent states to enhance outcome explanation.
Lastly, this general model framework can be extended to encompass multiple outcome models. For further details, see Handling multiple outcomes.
Given the complexity of manually specifying all model components, the kDGLM package includes a range of auxiliary functions to simplify this process. The subsequent section delves into these tools.
Single outcome models
The kDGLM package supports the joint modelling of multiple time series, each with it own structure and distribution (see Handling multiple outcomes). This flexibility comes with a somewhat complex syntax, designed to allow analysts to meticulously define every aspect of the model. While we have aimed to create an intuitive yet powerful syntax, we recognize that it may feel overwhelming for new users. To address this, the kDGLM package also provides a simplified syntax, similar to the lm and glm functions native to R. This simplified approach supports single-outcome models with any of the supported distributions, while still allowing for complex dynamic structures in all parameters of the observational distribution.
Lets consider the classic airline data, which is comprised of monthly totals of international airline passengers, from 1949 to 1960. We can adjust a simple Time Series model using the following code:
Detail about the plot method can be found in Filtering and smoothing,
for now we focus only on the usage of the kdglm
function. By the default, the intercept of a model is considered dynamic
in a discount factor of
.
One can specify the details of the intercept using the pol
function inside the formula:
One can also add more complex structures to the model using the functions , , , and :
fitted.data <- kdglm(c(AirPassengers) ~ pol(D = 0.99, order = 2) + har(period = 12) + noise(R1 = 0.01), family = Poisson)
plot(fitted.data)For more details, see Structures.
For dynamic regressions, the kdglm package adopts the same convetions as the lm and glm functions:
# Total number of cases
chickenPox$Total <- rowSums(chickenPox[, c(2, 3, 4, 6, 5)])
# Indicator of the introcution of the chicken pox vaccine to the national program of immunization
chickenPox$Vaccine <- chickenPox$date >= as.Date("2013-09-01")
fitted.data <- kdglm(`< 5 year` ~ pol(2, D = 0.95) + har(12, D = 0.975) + Vaccine,
N = chickenPox$Total,
family = Multinom,
data = chickenPox
)
plot(fitted.data, plot.pkg = "base")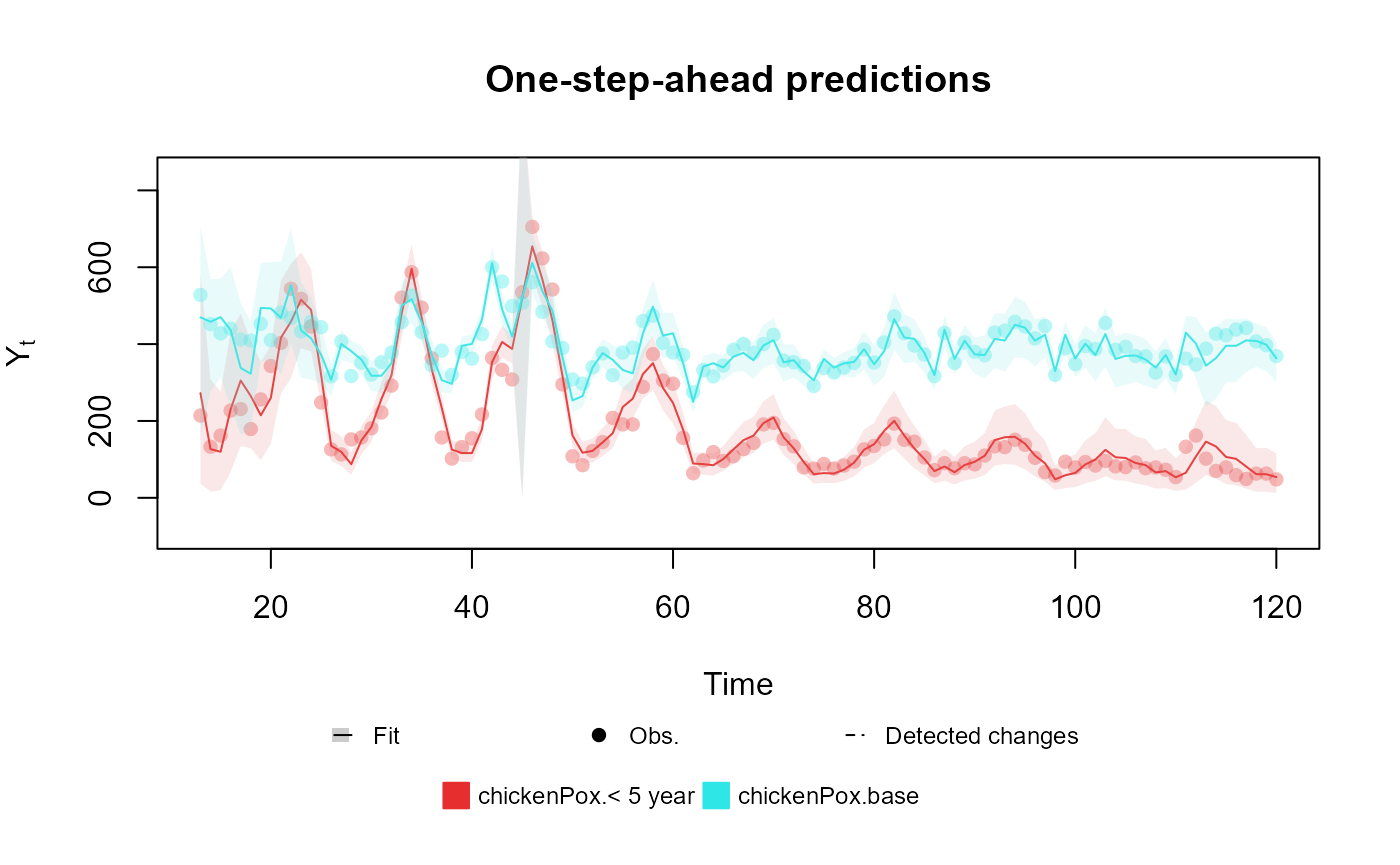
For the multinomial case, where we the outcome of the model is a vector, the user may include several formulas, one for each index of the outcome vector:
fitted.data <- kdglm(
`< 5 year` ~ pol(2, D = 0.95) + har(12, D = 0.975) + Vaccine,
`10 to 14 years` ~ pol(2, D = 0.95) + har(12, D = 0.975) + Vaccine,
`15 to 49 years` ~ pol(2, D = 0.95) + har(12, D = 0.975) + Vaccine,
`50 years or more` ~ pol(2, D = 0.95) + har(12, D = 0.975) + Vaccine,
N = chickenPox$Total,
family = Multinom,
data = chickenPox
)
plot(fitted.data, plot.pkg = "base")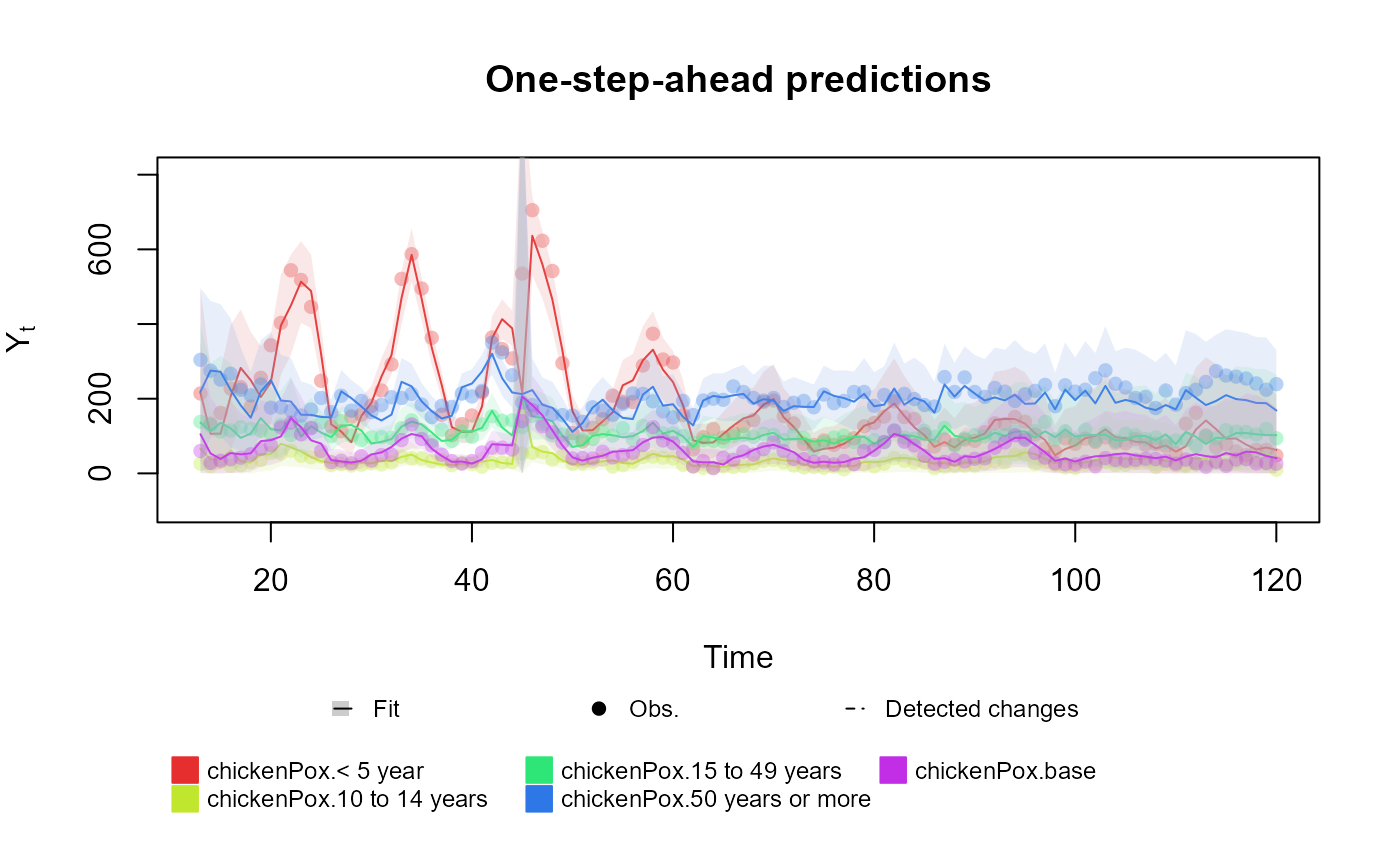
Lastly, some outcomes may require extra arguments for the parameters of the observational model. For instance, the kdglm package allows for dynamic structure for all parameters of a model, so for the Normal family, the user may include dynamic structure for both mean and variance:
fitted.data <- kdglm(corn.log.return ~ 1,
V = ~1,
family = Normal,
data = cornWheat[1:500, ]
)
plot(fitted.data, plot.pkg = "base")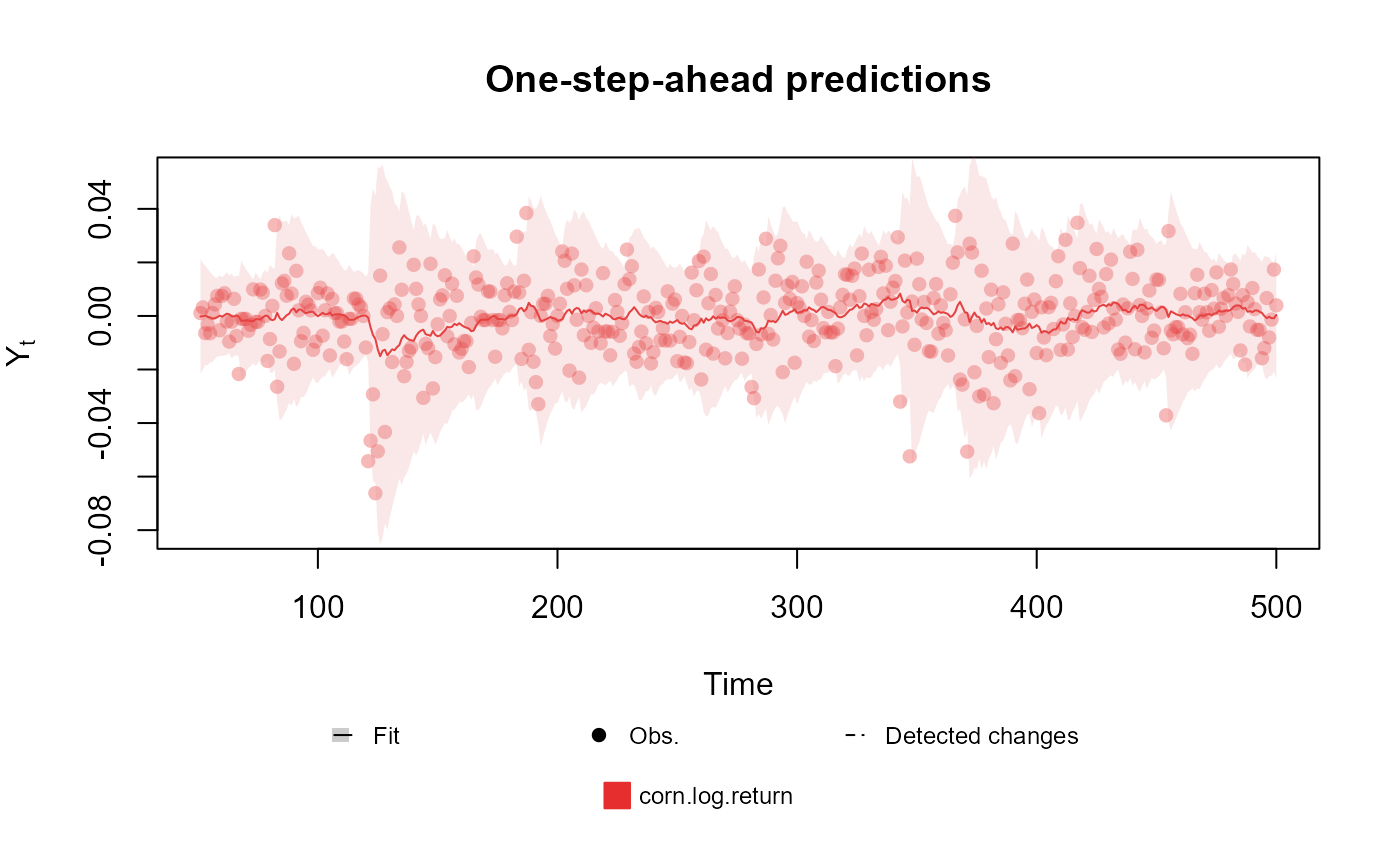
For more details about each outcome see Outcomes.